I Built an OO CLI App via New York Times API to Help Local Book Stores! Here's How!

I'm a life-long, self-directed learner with a love for libraries, documentation, and all things tech.
Currently serving the people at the Carnegie Library of Pittsburgh 📚 Formerly @ Codédex 👾 and Codecademy 🧑🏻💻
Extracurriculars (in no particular order): 🧑🏻🍳 Cooking 📖 Reading (mostly non-fic of all kinds) 🎸 Listening to/playing music 🎙️ Enjoying awesome podcasts. 🏃🏻 Running, walking, moving in general! :D
Thanks for reading!

For my first Flatiron School project, I built a Ruby CLI application that utilizes basic programming concepts, object-oriented programming and works with third-party data (through means like web scraping or APIs). My project uses the NYT Books API to fetch category and bestseller data for the
user to interact with. The user enters a date and picks a category to display the top 15 books from
that particular Bestseller List. They can then select a book to get more information about it (description, pricing, etc). At the end of the program, the user has the two last choices:
- end the program normally or...
- end and visit www.indiebound.org to purchase the selected book from a local book
store (to support them during the COVID-19 outbreak).
Full disclosure: the latter option may not work properly on your computer because
opening a third-party website from the terminal/ command may be interpreted as
virus-like by your operating system. So in case it doesn't work, I've provided the url text
in the output in the console. Just copy and paste it in you're good to go!
Pre-requisites
In order to get the most out of (and have fun with) this project, you need to have a good
understanding of the following:
Basic Ruby concepts (blocks, loops, variables, etc)
Object-oriented programming in Ruby (classes, attributes, object-relationships, etc)
Working with data from outside your program (scraping, web crawling, APIs, etc)
Using the NYT Books API (and environment variables)
I chose to work with an API because I've worked with them before in past projects.
The New York Times Books API is also better for the purposes of my project because I want to be able to fetch a bestsellers list by date and category easily. I enjoy learning about web scraping and how awesome gems like Nokogiri are for that task. But I felt that since there's an actual NYT API, they've already done much of the hard work of compiling and setting up all that data to be fetched.
In order to use the API, you'll need an API key. To get an API key, you'll need to sign up for an
account on the New York Times Developer Network. After obtaining the key, I highly recommend storing it inside an environment variable (preferably contained in a .env file). This is because, from what I've learned about APIs, you should never allow
your API key to be stored with your code. If it's exposed, hackers could potentially use the key with malicious intent.
Step 1: Wireframe; Plan it Out
This is the step that can either be the most fun or the most grueling. Though this first
step may take the most time out of all the others, it's vital to always be planning as much
as possible before actually starting to code.
Initially, I sat down and drew a rough wireframe of how the program would flow. I started with
a quick sketch on paper.

As nonsensical as this scribble may seem, it lays the groundwork for how my program is going to
work from start to finish. I just needed to jot down what was in my head so that I could refine it
into an idea that works. The scribbles eventually evolved into a flowchart like this:
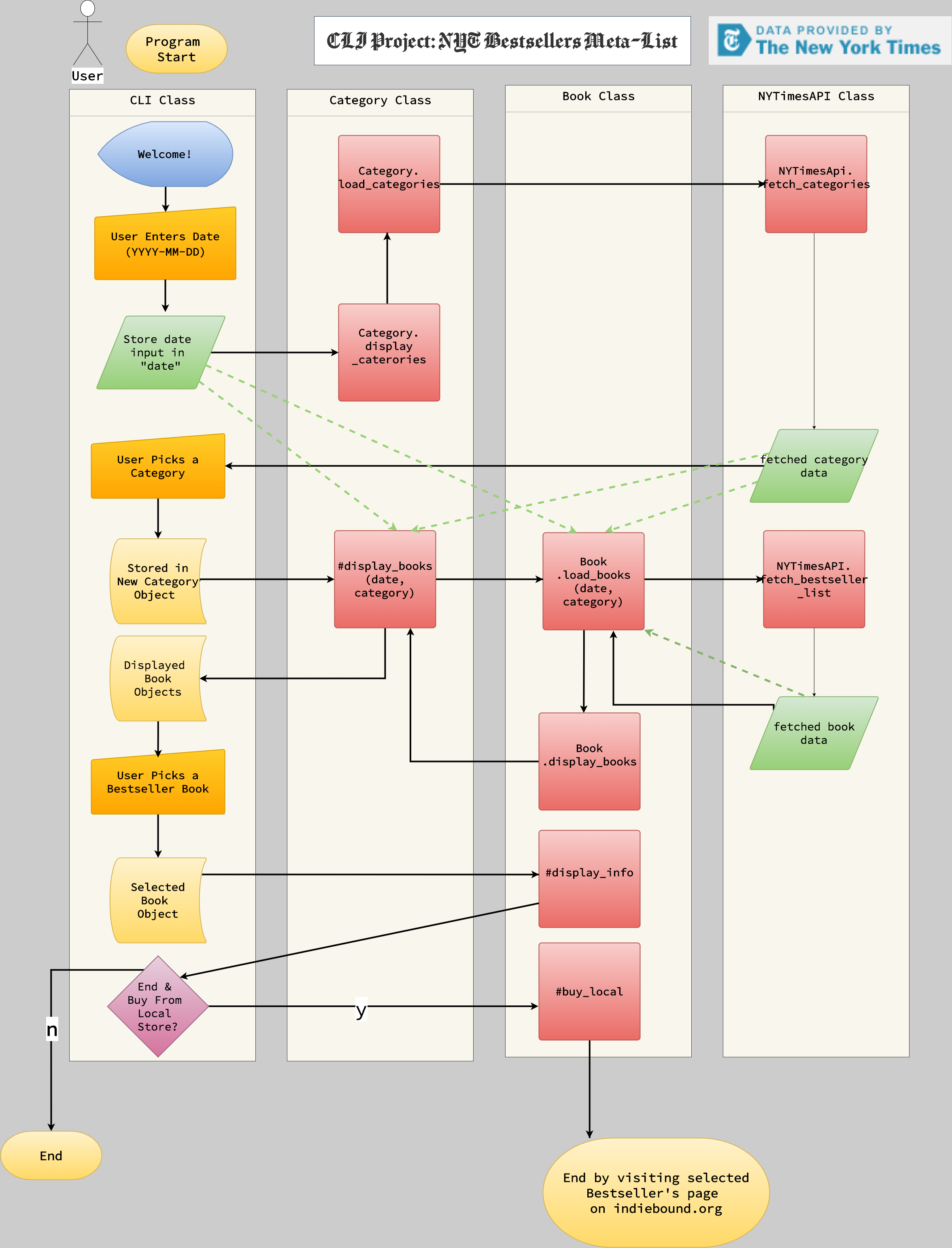
Step 2: Identify and Separate the Concerns
As Step 1 is finished, I start to think about what methods and attributes (loading books, displaying
categories, title, author, etc) can be structured as its own class?
In object-oriented programming, it's important to observe the separation of concerns by figuring out which class gets which "job". Since we're interacting with an API that fetches book and category data,
I think it makes sense to create the following classes:
An
NYTimesAPIclass- fetch, format and return category and book data
A
Categoryclass- each instance has many Book objects
- load/ display categories
- load books for a single Category instance
A
Bookclass- each instance belongs to a Category instance
- attributes such as title, author, description, etc.
- contains a
#buy_localmethod that helps you buy the book online
Since I want to keep my API key hidden from my actual code, I'll store to a .env as an environment variable. In past projects, I've found that storing API keys as an environment variable in your computer
greatly reduces the risk of exposure.
Thanks to the handy Ruby gem dotenv, we're able to load a custom-set environment variable from a .env file, store the key and use it to work with the
API (without exposing the key on the frontend).
Step 3: Build/ Test/ Refactor
After I've outlined the flow of my program and worked out what tools and gems will be helpful, it's
time to start building. Since I'm going to be using a bunch of Ruby gems, I'll set up the boilerplate code
of the project by:
- Making sure I have the
bundlergem installed (to keep my other gem dependencies up to date) - Creating a
Gemfilewith the this code:
source "https://rubygems.org"
# Specify your gem's dependencies in nyt_bestsellers_cli.gemspec
gemspec
gem "rake", "~> 12.0"
gem "rspec", "~> 3.0"
gem "rest-client"
gem "colorize"
Create the following folders:
bin(for executable files)config(for the program's environment settings)- 'lib' (for the actual source code)
Setting up the folder structure, I've found, is great for getting the ball rolling on building the project.
Step 4: Repeat Steps 1-3 until your project becomes an MVP
Experience shows that programming projects have bumps and setback -- sometimes, you just have
to reconsider your approach. The point it to get the project to a point where it can stand on its own
as a legitimate start-to-finish program; the minimum viable product.
Making the flowchart really helped me with understanding which class does what.
For the NYTimesAPI class, I'm not concerned with what it can do on an instance level, just a class level. Therefore, it's only responsibility should be to fetch data from the API. The only class-level attributes it
should have is a @@base_url (needed for all API calls) and the @@api_key that refers to the
environment variable we discussed earlier.
class NYTimesAPI
@@base_url = "https://api.nytimes.com/svc/books/v3/lists/"
@@api_key = ENV["NYT_API_KEY"]
def self.fetch_bestseller_list(date, category)
...
end
def self.fetch_categories
...
end
end
On a class level, the Category class should load the data fetched from the NYTimesAPI. Once the
data is fetched, there should be a method to display them. There should be instance-level attributes and
methods because there are different categories and each have many Book objects. It should definitely
have an attribute that stores the URL-friendly version of the category name (for fetching data in NYTimesAPI).
class Category
@@all = [] # for storing the Book objects
attr_accessor :display_name, :list_name_encoded
def self.load_categories
...
end
def self.display_categories
...
end
def display_books(date, category)
...
end
end
The Book class maintains the "belongs-to" relationship with the Category class. After all, a single
category can "have many" books! On a class-level, a Book keeps a record of all of its instances through@@all. Like categories, books need a way to load themselves and be displayed. This can also be done on the class level. Instances of any book should have common book traits (titles, authors, descriptions,
etc). And each instance should have a way of displaying that information.
class Book
@@all = []
attr_accessor :title, :author, :category, :description, :price, :rank, :local_link
def self.load_books(date, category)
...
end
def self.display_books
end
end
Conclusion
Any project I've ever completed is subject to improvement. This one is no exception. The code examples
I gave were later expanded upon. Some methods were split into smaller helper-methods. The data that
was fetched from the API didn't come in a format that's reader-friendly. I had to build a method to take
care of that. There's always something that could make the program more efficient, readable and
maintainable. I made a lot of mistakes along the way with this project, but I feel I also made a lot of
progress. This was the first program I built that could actually be helpful. (In this case, independent book stores struggling to stay afloat during the COVID pandemic) I'm excited to take what I've learned to future projects!
You should fork/ clone the project from my repo on Github and try it yourself!
Happy Coding!